
From Prediction to Impact: Why Causal ML Matters in Modern Marketing

Over the last decade, data science has become a cornerstone of modern marketing. Organizations have invested millions in data platforms, feature stores, machine learning pipelines, and experimentation frameworks. They can now forecast churn with impressive accuracy, estimate conversion probabilities, and rank customers by propensity to buy in real time. On paper, this looks like maturity.
But there is a fundamental question that most of these systems still fail to answer:
Are our actions actually making a difference?
This question becomes unavoidable once we recognize a simple fact: marketing is not just about forecasting behavior, it is about influencing it. Decisions always involve an intervention: sending an email, pushing a notification, offering a discount, calling a customer. Prediction alone cannot tell us whether these actions cause the desired outcome, or whether the same result would have happened anyway.
Causal ML and AI address this gap. They provides a principled framework to move from predicting outcomes to optimizing decisions, enabling data scientists to quantify the true incremental effect of marketing actions and support more effective and cost-aware strategies.
Why Causality Is Becoming Central in Data Science
Causality is no longer an academic niche. It is becoming a core capability for organizations that want to move from reporting performance to driving impact.
Research conferences, industry events, and technical roadmaps increasingly highlight causal inference, uplift modeling, and experimentation as strategic priorities. The job market reflects the same shift: companies are not just hiring modelers, but decision scientists, professionals who can quantify the incremental impact of actions.
This shift builds on decades of work by Judea Pearl and the causal inference community, which provided a formal framework to answer questions that predictive ML alone cannot resolve:
Did this campaign actually generate incremental revenue?
Would this customer have converted without the discount?
Who should we target to maximize true uplift, not just response rate?
These are not forecasting problems. They are decision problems.
Why Now?
Causality is becoming central because the business context has changed:
Interventions are expensive. Wrong actions burn budget and erode margins.
Customers are sensitive. Over-contacting reduces trust and long-term value.
Predictive ML has plateaued. Many organizations have already captured the “easy gains.”
Tooling is mature. Libraries like DoWhy, EconML, CausalML, and Double ML frameworks make causal modeling operational.
Where Causal ML Is Used
While marketing is a natural starting point, the same logic applies across domains:
Marketing & Growth: uplift modeling, personalization, pricing
Product & UX: feature impact, beyond-average A/B testing
Healthcare: treatment effectiveness, personalization
Economics & Policy: program evaluation
Operations: impact-aware optimization
Across sectors, the objective is the same: measure the effect of actions, not just detect patterns.
Correlation tells us what is likely to happen.
Causality tells us what will change if we act.
And when every action has a cost, that difference defines competitive advantage.
The Limits of Traditional Marketing Analytics
Marketing analytics tasks can be broadly categorized into three levels:
Descriptive: What happened?
Predictive: What is likely to happen?
Prescriptive: What should we do?
Traditional marketing analytics often excels at the first two levels. Campaign analysis is typically based on metrics such as:
Conversion rate after a contact
Number of purchases following a promotion
Click-through rate or engagement uplift
These metrics are not wrong: they describe observed behavior and can support forecasting. However, they often fail when used to guide decisions, because they do not isolate the effect of the action itself.
In the following sections, we examine two common scenarios in which descriptive and predictive approaches are misleading, and why a causal perspective is required.
When Description Is Misleading: Simpson’s Paradox in Marketing
Descriptive analyses often reveal strong associations between marketing actions and outcomes. For instance, historical data may show that customers who are contacted by a retention campaign exhibit higher churn rates than those who are not. A purely descriptive reading of this evidence would suggest that the campaign is ineffective or even harmful.
However, such conclusions can be deeply misleading. The key question for decision-making is not what is associated with churn, but what actually changes because we intervene. Answering this question requires going beyond description and correlation.
The issue arises because treatment assignment is not random. Customers perceived as high risk are more likely to be contacted and, independently, have a higher intrinsic probability of churn. This confounding effect dominates aggregate statistics and distorts the observed relationship between contact and churn. Let’s see it in an example.
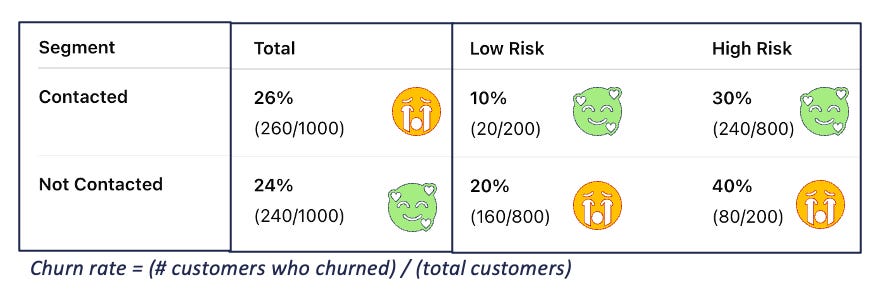
The figure illustrates a classic example of the limits of correlation, commonly associated with Simpson’s Paradox. When looking at the aggregated data, the churn rate among contacted customers appears worse than that of non-contacted ones, suggesting that the campaign is ineffective. However, once the population is split into Low Risk and High Risk segments, a different picture emerges:
within each segment, contacted customers churn less than non-contacted ones;
when the segments are aggregated, the effect reverses.
The paradox arises because treatment assignment is not random. High-risk customers are more likely to be contacted and, at the same time, have a higher intrinsic probability of churn. This confounding effect dominates the aggregate result. This mechanism becomes clear when looking at the causal graph in the next figure.
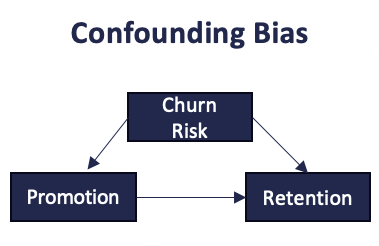
Causal graphs are simple diagrams that encode assumed cause–effect relationships between variables. Here, customer risk is a confounder: it affects both the likelihood of being contacted and the probability of churn. As a result, the observed correlation mixes the effect of the intervention with the effect of risk. From a causal standpoint, the remedy is to control for the confounder, by stratifying, adjusting, or, ideally, randomizing the treatment. Once this path is blocked, the true impact of contacting customers can be correctly assessed.
Without a causal perspective, marketing performance can be systematically misestimated, leading teams to optimize apparent metrics rather than true decision impact.
When Prediction Is Not Actionable: From Propensity to Uplift Modeling
Traditional predictive models are designed to estimate the likelihood of an outcome. In marketing, they typically answer questions such as:
Which customers are most likely to buy?
Which customers are at risk of churning?
While these models are often accurate in ranking customers by propensity, they are not sufficient for decision-making. A high predicted probability does not imply that an action will be effective. In many cases, the predicted outcome would occur even in the absence of any intervention.
Causal machine learning reframes the problem by shifting the focus from outcome prediction to impact prediction:
Which customers will buy because we contact them?
Which customers will stay because we intervene?
This distinction is crucial: predictive models estimate correlations, whereas marketing actions require estimates of incremental effects. This shift naturally leads to uplift modeling and treatment effect estimation.
In classical uplift modeling, customers can be conceptually grouped into four categories, which are particularly relevant in marketing scenarios such as churn prevention or cross-selling:
Sure Things – customers who will convert regardless of the campaign
Lost Causes – customers who will not convert even if contacted
Persuadable – customers who will convert only if contacted
Do-Not-Disturb – customers who would have converted but are negatively affected by the campaign
Only Persuadable generate true incremental value. Predictive models that rank customers by propensity alone are unable to distinguish them from Sure Things or Do-Not-Disturb customers, despite their very different implications for decision-making.
Uplift modeling explicitly targets this distinction, representing a natural evolution of predictive analytics toward decision-aware modeling, bridging the gap between prediction and prescription.
Just Enough Theory to Think Causally
You do not need a PhD in statistics to apply causal reasoning effectively. However, a few foundational ideas are essential. A useful mental model is:
Causal Effect = Observed Association + Bias
Observed differences between treated and untreated groups are almost always contaminated by bias due to confounding, selection effects, or measurement issues. The goal of causal inference is to eliminate or control this bias.
Randomized Experiments (RTE)
Randomized controlled experiments and A/B tests address bias by design. Randomization ensures that treated and untreated groups are statistically comparable. However, in practice:
Experiments are expensive
Randomization may be infeasible
Business constraints limit experimentation
Observational Data
The core problem with observational data is that correlation no longer implies causation. Differences between treated and untreated groups may reflect underlying structural differences rather than true causal effects. Bias is therefore not removed automatically and must be handled explicitly. Key concepts include:
Confounders: variables (X) affecting both treatment (T) and outcome (Y)
Colliders: variables that introduce bias when conditioned on
Mediators: variables through which the treatment exerts its effect
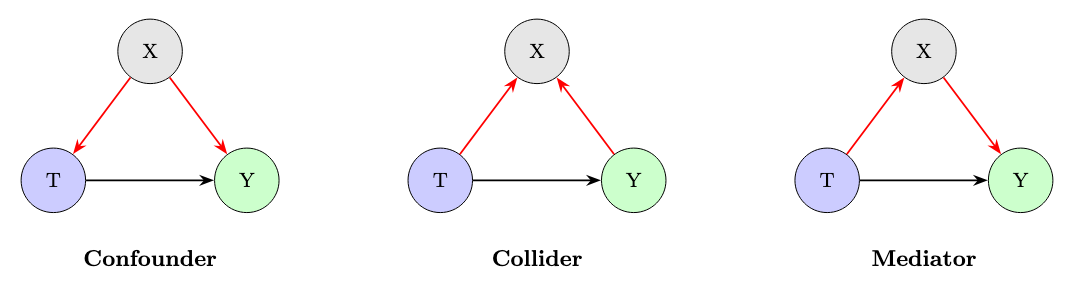
Causal thinking helps determine what to control for, and what to avoid controlling for. As discussed earlier with the example of Simpson’s paradox, confounders require stratification or adjustment: when a variable influences both treatment and outcome, grouping by it reveals the true causal relationship.
Colliders, however, behave in the opposite way and are a common pitfall. A collider is a variable that is influenced by both the treatment and the outcome. Conditioning on it (for example by filtering, grouping, or controlling for it) creates a spurious association that did not exist before.
A classic example is selecting only hospitalized patients when studying the effect of a drug on recovery: hospitalization is influenced by both treatment and disease severity, and conditioning on it can reverse or distort the estimated effect. The key rule is simple: with confounders we should adjust; with colliders we should not.
Frameworks such as do-calculus, the back-door criterion, and the front-door criterion provide systematic and often automatic ways to decide which variables to condition on and which to avoid, making these distinctions explicit and reducing the risk of intuitive but incorrect adjustments.
Causal Inference in Practice
One of the most popular is DoWhy, which formalizes causal inference into four intuitive steps:
Model – Define the causal graph (assumptions made explicit)
Identify – Determine whether the causal effect is identifiable
Estimate – Compute the treatment effect using appropriate methods
Refute – Stress-test results with robustness checks
This approach bridges the gap between theory and production-ready analytics. Indeed, these steps have been rooted in the work of Judea Pearl and the causal inference community, which introduced a rigorous, graph-based language to reason about cause and effect. Unlike traditional statistical pipelines, where assumptions often remain implicit, this framework forces them to be stated clearly and checked systematically.
The modeling step is particularly novel for many data scientists. In standard DS workflows, “modeling” usually means choosing an algorithm; here, it means modeling the data-generating process itself. This shift represents a conceptual change: from fitting patterns to encoding causal assumptions.
Causal Thinking: Risks, Pitfalls, and Practical Takeaways
Causal inference provides powerful tools for decision-making, but it is not risk-free.
Wrong assumptions lead to wrong conclusions. Poor data quality amplifies bias. Hidden confounders cannot be fixed by algorithms alone. Overconfidence in point estimates can mislead stakeholders. Excessive complexity can hinder communication and adoption.
A causal approach therefore requires:
strong domain knowledge,
transparent assumptions,
rigorous validation,
humility about uncertainty.
When applied responsibly, however, causal inference enables a fundamental evolution in marketing analytics. Instead of asking “What happened?” or “What is likely to happen?”, organizations can finally ask:
“What should we do next to maximize impact?”
By adopting a causal mindset and leveraging modern tools, teams can:
measure the true incremental effect of campaigns,
target only customers who can be influenced,
reduce waste and customer fatigue,
move from prediction toward prescriptive decision-making.
Causality is not just a theoretical upgrade.
It is a practical advantage for building more effective, efficient, and responsible marketing systems.